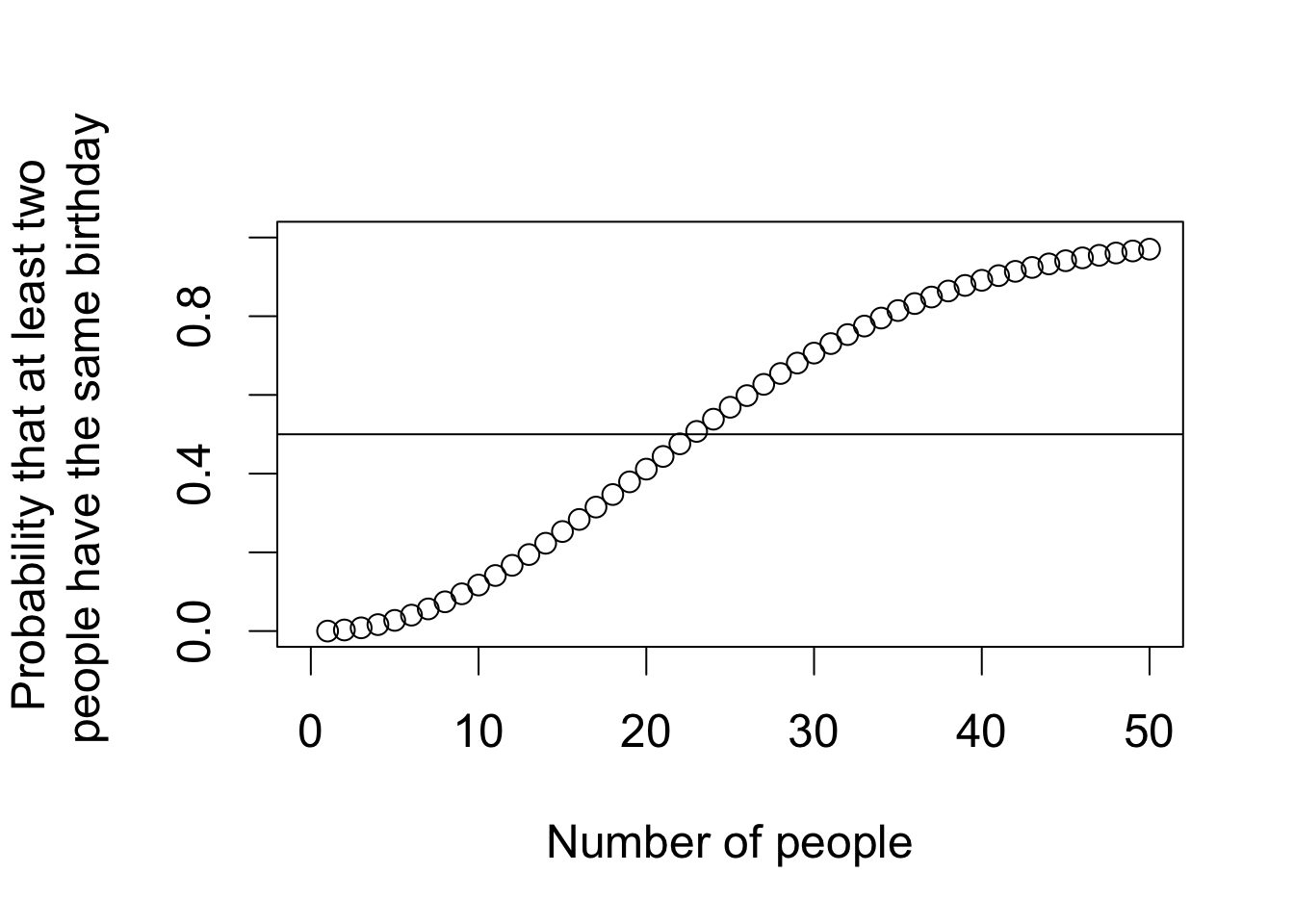
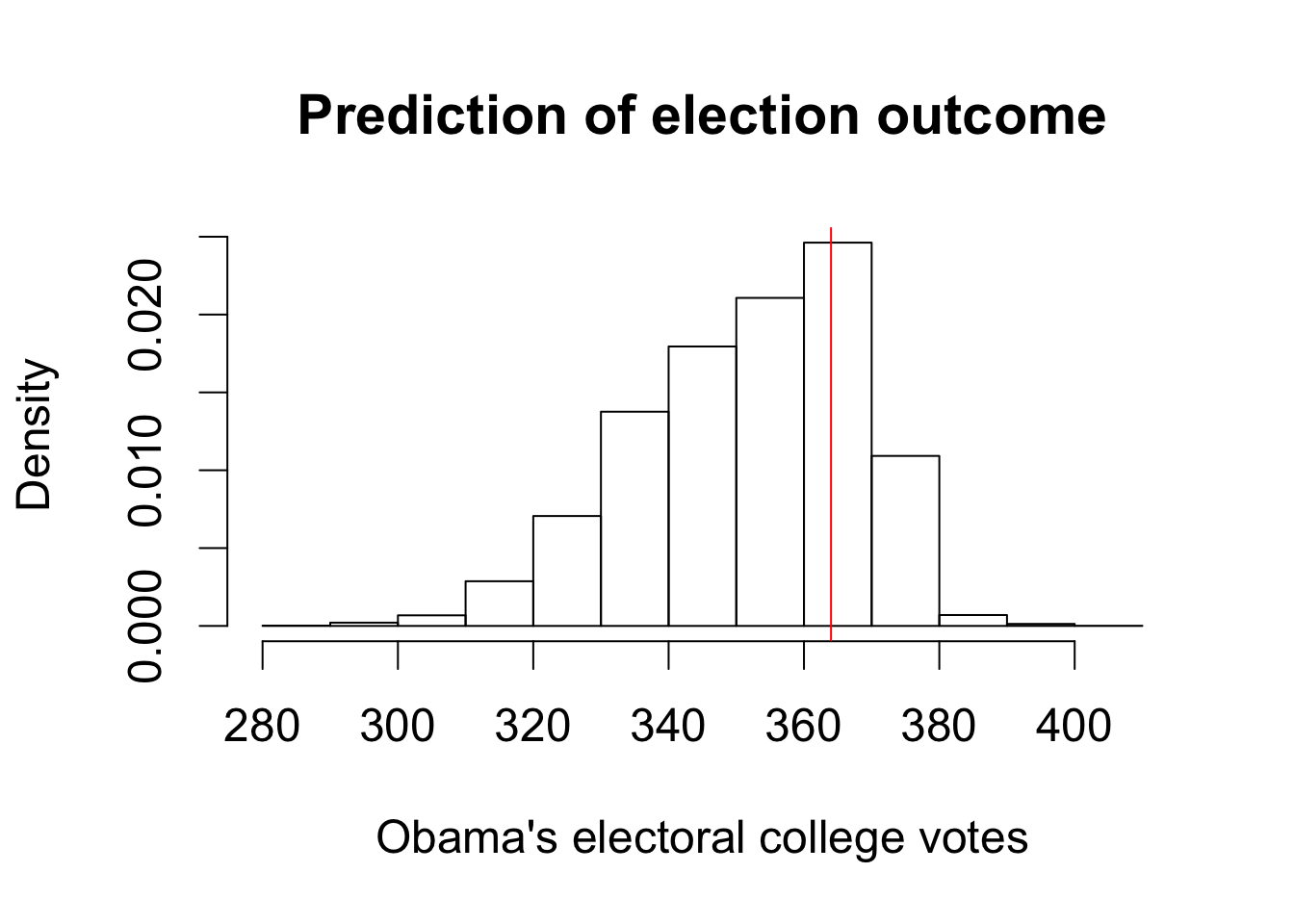
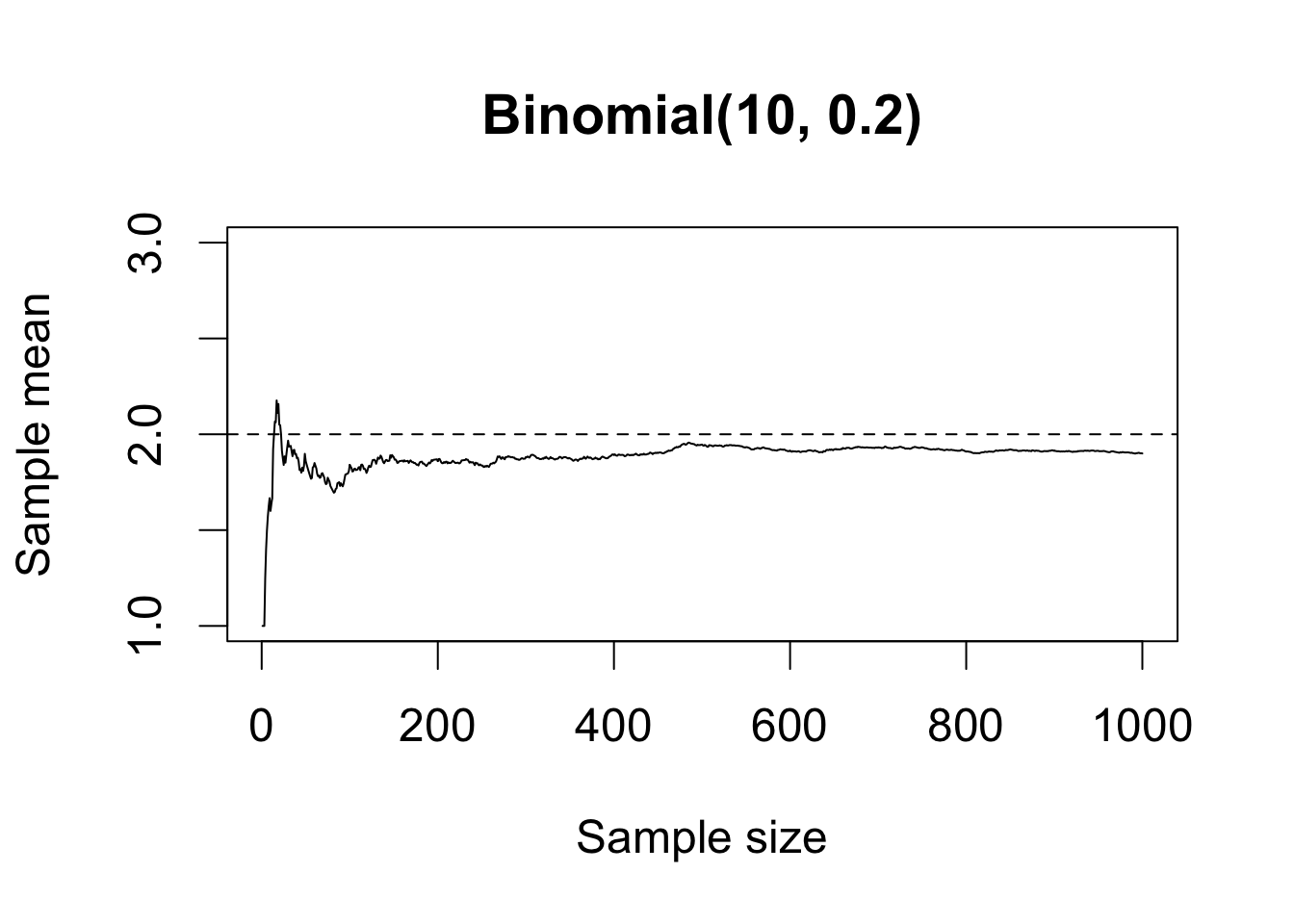
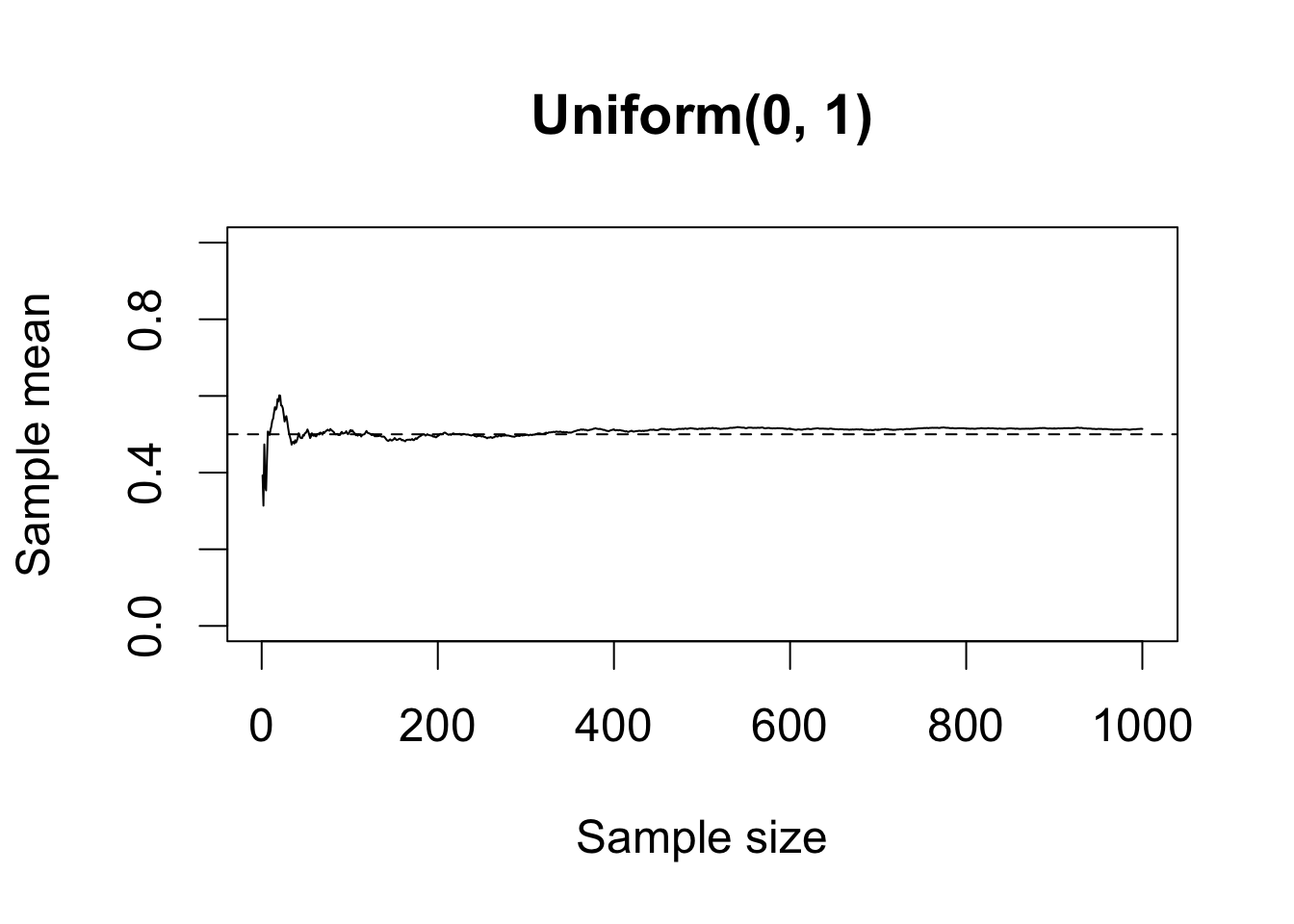
Section 6.2.1: Conditional, Marginal, and Joint Probabilities
data("FLVoters", package = "qss")
dim(FLVoters) # before removal of missing data
## [1] 10000 6
FLVoters <- na.omit(FLVoters)
dim(FLVoters) # after removal
## [1] 9113 6
margin.race <- prop.table(table(FLVoters$race))
margin.race
##
## asian black hispanic native other white
## 0.019203336 0.131021617 0.130802151 0.003182267 0.034017338 0.681773291
margin.gender <- prop.table(table(FLVoters$gender))
margin.gender
##
## f m
## 0.5358279 0.4641721
prop.table(table(FLVoters$race[FLVoters$gender == "f"]))
##
## asian black hispanic native other white
## 0.016997747 0.138849068 0.136391563 0.003481466 0.032357157 0.671922998
joint.p <- prop.table(table(race = FLVoters$race, gender = FLVoters$gender))
joint.p
## gender
## race f m
## asian 0.009107868 0.010095468
## black 0.074399210 0.056622408
## hispanic 0.073082410 0.057719741
## native 0.001865467 0.001316800
## other 0.017337869 0.016679469
## white 0.360035115 0.321738176
rowSums(joint.p)
## asian black hispanic native other white
## 0.019203336 0.131021617 0.130802151 0.003182267 0.034017338 0.681773291
colSums(joint.p)
## f m
## 0.5358279 0.4641721
FLVoters$age.group <- NA # initialize a variable
FLVoters$age.group[FLVoters$age <= 20] <- 1
FLVoters$age.group[FLVoters$age > 20 & FLVoters$age <= 40] <- 2
FLVoters$age.group[FLVoters$age > 40 & FLVoters$age <= 60] <- 3
FLVoters$age.group[FLVoters$age > 60] <- 4
joint3 <-
prop.table(table(race = FLVoters$race, age.group = FLVoters$age.group,
gender = FLVoters$gender))
joint3
## , , gender = f
##
## age.group
## race 1 2 3 4
## asian 0.0001097333 0.0026336004 0.0041698672 0.0021946670
## black 0.0016460002 0.0280917371 0.0257873368 0.0188741358
## hispanic 0.0015362669 0.0260068035 0.0273236036 0.0182157358
## native 0.0001097333 0.0004389334 0.0006584001 0.0006584001
## other 0.0003292000 0.0062548008 0.0058158674 0.0049380007
## white 0.0059256008 0.0796664106 0.1260836168 0.1483594864
##
## , , gender = m
##
## age.group
## race 1 2 3 4
## asian 0.0002194667 0.0028530670 0.0051574674 0.0018654669
## black 0.0016460002 0.0228245364 0.0189838692 0.0131680018
## hispanic 0.0016460002 0.0197520026 0.0221661363 0.0141556019
## native 0.0000000000 0.0004389334 0.0003292000 0.0005486667
## other 0.0004389334 0.0069132009 0.0055964007 0.0037309338
## white 0.0040601339 0.0750576100 0.1184022825 0.1242181499
## marginal probabilities for age groups
margin.age <- prop.table(table(FLVoters$age.group))
margin.age
##
## 1 2 3 4
## 0.01766707 0.27093164 0.36047405 0.35092725
## P(black and female | above 60)
joint3["black", 4, "f"] / margin.age[4]
## 4
## 0.05378361
## two-way joint probability table for age group and gender
joint2 <- prop.table(table(age.group = FLVoters$age.group,
gender = FLVoters$gender))
joint2
## gender
## age.group f m
## 1 0.009656535 0.008010534
## 2 0.143092286 0.127839350
## 3 0.189838692 0.170635356
## 4 0.193240426 0.157686821
joint2[4, "f"] # P(above 60 and female)
## [1] 0.1932404
## P(black | female and above 60)
joint3["black", 4, "f"] / joint2[4, "f"]
## [1] 0.09767178
Section 6.2.2: Independence
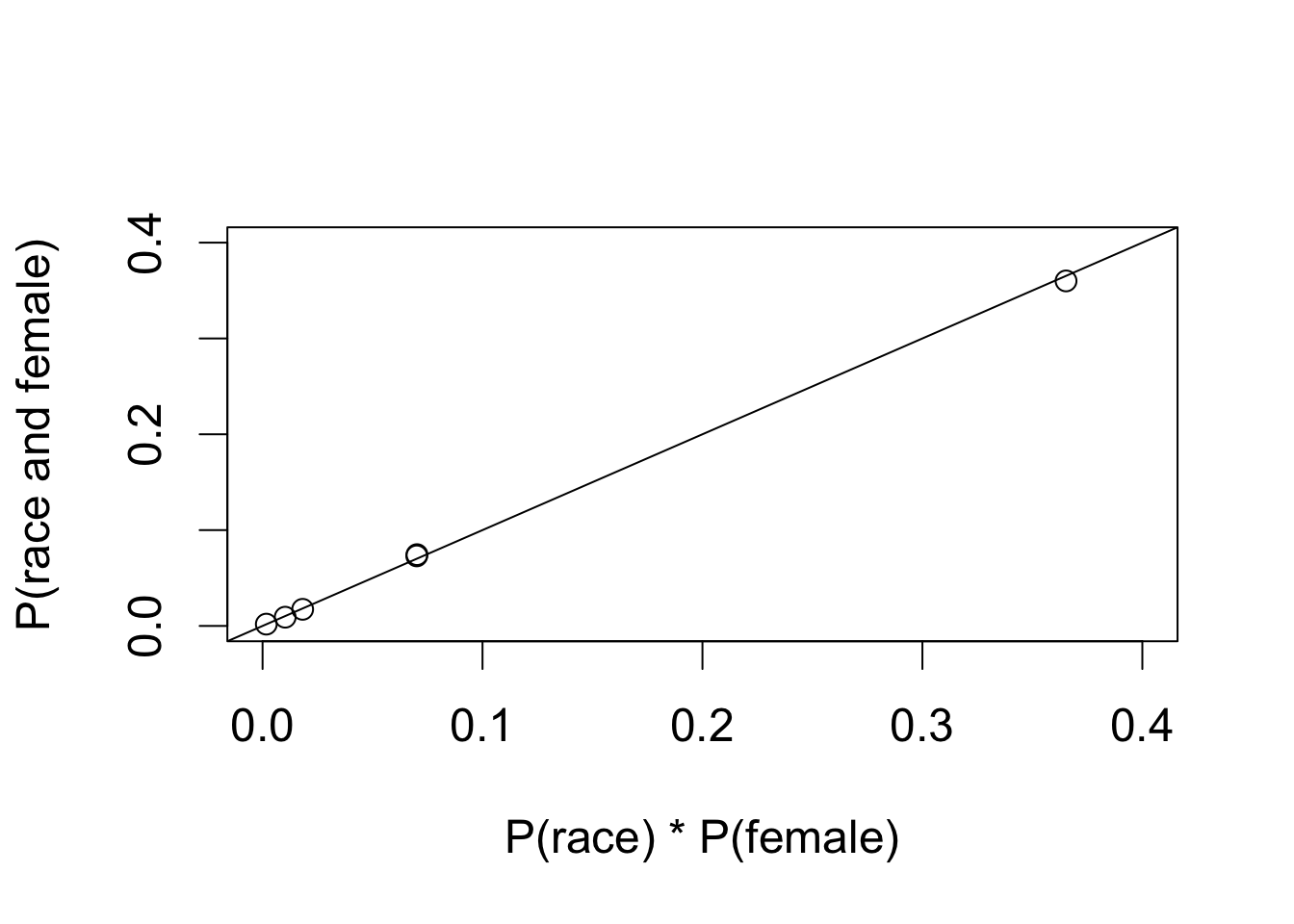
par(cex = 1.5)
plot(c(margin.race * margin.gender["f"]), # product of marginal probs.
c(joint.p[, "f"]), # joint probabilities
xlim = c(0, 0.4), ylim = c(0, 0.4),
xlab = "P(race) * P(female)", ylab = "P(race and female)")
abline(0, 1) # 45 degree line
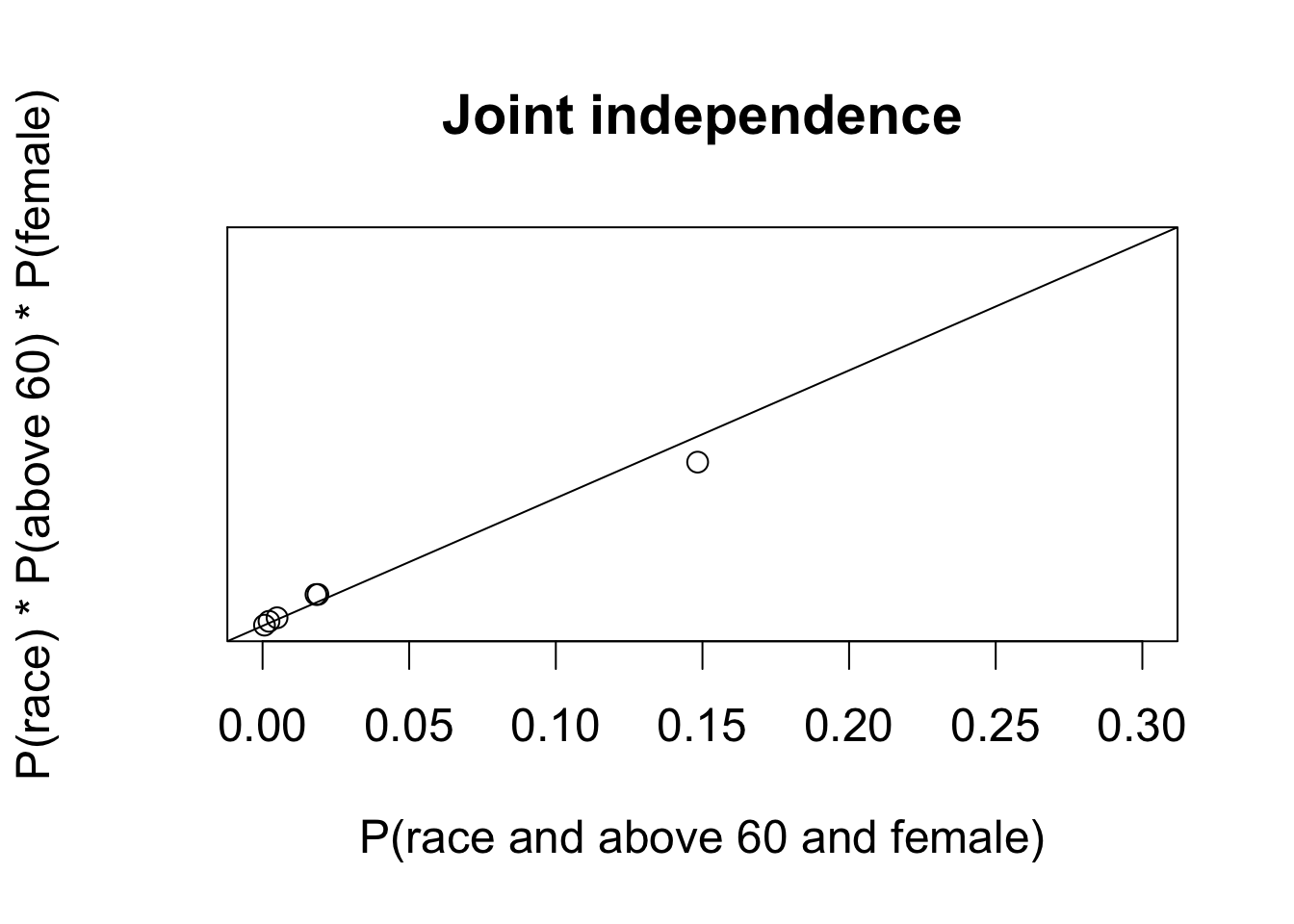
par(cex = 1.5)
## joint independence
plot(c(joint3[, 4, "f"]), # joint probability
margin.race * margin.age[4] * margin.gender["f"], # product of marginals
xlim = c(0, 0.3), ylim = c(0, 0.3), main = "Joint independence",
xlab = "P(race and above 60 and female)",
ylab = "P(race) * P(above 60) * P(female)")
abline(0, 1)
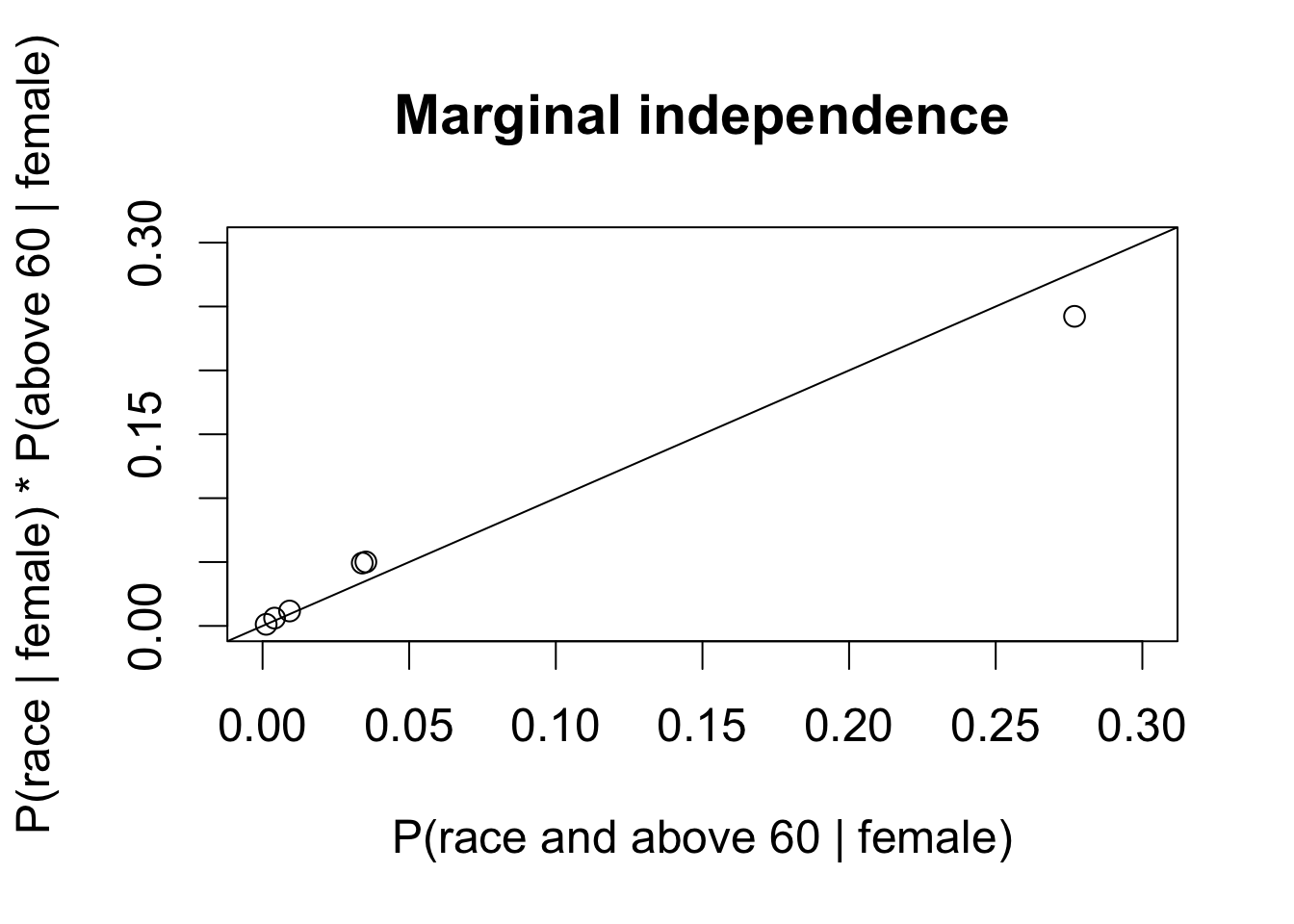
## conditional independence given female
plot(c(joint3[, 4, "f"]) / margin.gender["f"], # joint prob. given female
## product of marginals
(joint.p[, "f"] / margin.gender["f"]) *
(joint2[4, "f"] / margin.gender["f"]),
xlim = c(0, 0.3), ylim = c(0, 0.3), main = "Marginal independence",
xlab = "P(race and above 60 | female)",
ylab = "P(race | female) * P(above 60 | female)")
abline(0, 1)
sims <- 1000
doors <- c("goat", "goat", "car")
result.switch <- result.noswitch <- rep(NA, sims)
for (i in 1:sims) {
## randomly choose the initial door
first <- sample(1:3, size = 1)
result.noswitch[i] <- doors[first]
remain <- doors[-first] # remaining two doors
## Monty chooses one door with a goat
monty <- sample((1:2)[remain == "goat"], size = 1)
result.switch[i] <- remain[-monty]
}
mean(result.noswitch == "car")
## [1] 0.324
mean(result.switch == "car")
## [1] 0.676
Section 6.2.4: Predicting Race Using Surname and Residence Location
data("cnames", package = "qss")
dim(cnames)
## [1] 151671 7
x <- c("blue", "red", "yellow")
y <- c("orange", "blue")
## match x with y
match(x, y) # `blue' appears in the 2nd element of y
## [1] 2 NA NA
## match y with x
match(y, x) # `blue' appears in the 1st element of x
## [1] NA 1
FLVoters <- FLVoters[!is.na(match(FLVoters$surname, cnames$surname)), ]
dim(FLVoters)
## [1] 8022 7
whites <- subset(FLVoters, subset = (race == "white"))
w.indx <- match(whites$surname, cnames$surname)
head(w.indx)
## [1] 8610 237 4131 2244 27852 3495
## relevant variables
vars <- c("pctwhite", "pctblack", "pctapi", "pcthispanic", "pctothers")
mean(apply(cnames[w.indx, vars], 1, max) == cnames$pctwhite[w.indx])
## [1] 0.950218
## blacks
blacks <- subset(FLVoters, subset = (race == "black"))
b.indx <- match(blacks$surname, cnames$surname)
mean(apply(cnames[b.indx, vars], 1, max) == cnames$pctblack[b.indx])
## [1] 0.1604824
## Hispanics
hispanics <- subset(FLVoters, subset = (race == "hispanic"))
h.indx <- match(hispanics$surname, cnames$surname)
mean(apply(cnames[h.indx, vars], 1, max) == cnames$pcthispanic[h.indx])
## [1] 0.8465298
## Asians
asians <- subset(FLVoters, subset = (race == "asian"))
a.indx <- match(asians$surname, cnames$surname)
mean(apply(cnames[a.indx, vars], 1, max) == cnames$pctapi[a.indx])
## [1] 0.5642857
indx <- match(FLVoters$surname, cnames$surname)
## whites false discovery rate
1 - mean(FLVoters$race[apply(cnames[indx, vars], 1, max) ==
cnames$pctwhite[indx]] == "white")
## [1] 0.1973603
## black false discovery rate
1 - mean(FLVoters$race[apply(cnames[indx, vars], 1, max) ==
cnames$pctblack[indx]] == "black")
## [1] 0.3294574
## Hispanic false discovery rate
1 - mean(FLVoters$race[apply(cnames[indx, vars], 1, max) ==
cnames$pcthispanic[indx]] == "hispanic")
## [1] 0.2274755
## Asian false discovery rate
1 - mean(FLVoters$race[apply(cnames[indx, vars], 1, max) ==
cnames$pctapi[indx]] == "asian")
## [1] 0.3416667
data("FLCensus", package = "qss")
## compute proportions by applying weighted.mean() to each column
race.prop <-
apply(FLCensus[, c("white", "black", "api", "hispanic", "others")],
2, weighted.mean, weights = FLCensus$total.pop)
race.prop # race proportions in Florida
## white black api hispanic others
## 0.60451586 0.13941679 0.02186662 0.21279972 0.02140101
total.count <- sum(cnames$count)
## P(surname | race) = P(race | surname) * P(surname) / P(race)
cnames$name.white <- (cnames$pctwhite / 100) *
(cnames$count / total.count) / race.prop["white"]
cnames$name.black <- (cnames$pctblack / 100) *
(cnames$count / total.count) / race.prop["black"]
cnames$name.hispanic <- (cnames$pcthispanic / 100) *
(cnames$count / total.count) / race.prop["hispanic"]
cnames$name.asian <- (cnames$pctapi / 100) *
(cnames$count / total.count) / race.prop["api"]
cnames$name.others <- (cnames$pctothers / 100) *
(cnames$count / total.count) / race.prop["others"]
FLVoters <- merge(x = FLVoters, y = FLCensus, by = c("county", "VTD"),
all = FALSE)
## P(surname | residence) = sum_race P(surname | race) P(race | residence)
indx <- match(FLVoters$surname, cnames$surname)
FLVoters$name.residence <- cnames$name.white[indx] * FLVoters$white +
cnames$name.black[indx] * FLVoters$black +
cnames$name.hispanic[indx] * FLVoters$hispanic +
cnames$name.asian[indx] * FLVoters$api +
cnames$name.others[indx] * FLVoters$others
## P(race | surname, residence) = P(surname | race) * P(race | residence)
## / P(surname | residence)
FLVoters$pre.white <- cnames$name.white[indx] * FLVoters$white /
FLVoters$name.residence
FLVoters$pre.black <- cnames$name.black[indx] * FLVoters$black /
FLVoters$name.residence
FLVoters$pre.hispanic <- cnames$name.hispanic[indx] * FLVoters$hispanic /
FLVoters$name.residence
FLVoters$pre.asian <- cnames$name.asian[indx] * FLVoters$api /
FLVoters$name.residence
FLVoters$pre.others <- 1 - FLVoters$pre.white - FLVoters$pre.black -
FLVoters$pre.hispanic - FLVoters$pre.asian
## relevant variables
vars1 <- c("pre.white", "pre.black", "pre.hispanic", "pre.asian",
"pre.others")
## whites
whites <- subset(FLVoters, subset = (race == "white"))
mean(apply(whites[, vars1], 1, max) == whites$pre.white)
## [1] 0.9371366
## blacks
blacks <- subset(FLVoters, subset = (race == "black"))
mean(apply(blacks[, vars1], 1, max) == blacks$pre.black)
## [1] 0.6474954
## Hispanics
hispanics <- subset(FLVoters, subset = (race == "hispanic"))
mean(apply(hispanics[, vars1], 1, max) == hispanics$pre.hispanic)
## [1] 0.85826
## Asians
asians <- subset(FLVoters, subset = (race == "asian"))
mean(apply(asians[, vars1], 1, max) == asians$pre.asian)
## [1] 0.6071429
## proportion of blacks among those with surname "White"
cnames$pctblack[cnames$surname == "WHITE"]
## [1] 27.38
## predicted probability of being black given residence location
summary(FLVoters$pre.black[FLVoters$surname == "WHITE"])
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.005207 0.081154 0.176265 0.264042 0.320035 0.983717
## whites
1 - mean(FLVoters$race[apply(FLVoters[, vars1], 1, max) ==
FLVoters$pre.white] == "white")
## [1] 0.1187425
## blacks
1 - mean(FLVoters$race[apply(FLVoters[, vars1], 1, max) ==
FLVoters$pre.black] == "black")
## [1] 0.2346491
## Hispanics
1 - mean(FLVoters$race[apply(FLVoters[, vars1], 1, max) ==
FLVoters$pre.hispanic] == "hispanic")
## [1] 0.2153709
## Asians
1 - mean(FLVoters$race[apply(FLVoters[, vars1], 1, max) ==
FLVoters$pre.asian] == "asian")
## [1] 0.3461538